| KNN算法 | 您所在的位置:网站首页 › stata命令discrim knn › KNN算法 |
KNN算法
|
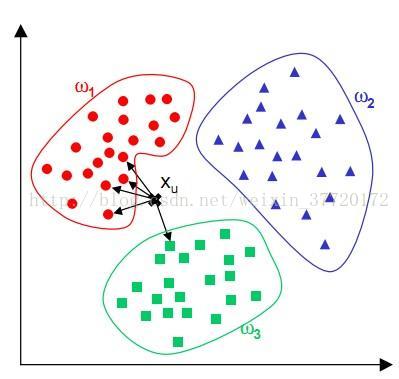
KNN邻近算法,或者说K最近邻(k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。 这个算法广泛用于机器学习中。比如上图中,我们给定了三个训练集w1,w2,w3。然后给出Xu来,并判断Xu属于那一个集合。 这时我们就需要去算他到以上每个集合中每一个元素的欧几里德距离(或者曼哈顿距离),然后对这些距离进行排序,并求出距离最近的前K位元素。然后根据这K位数据中,各集合所占的比例,得出比例最高的集合,这个未知元素便属于最近邻中占比最高的集合。 欧几里德距离
曼哈顿距离
下面给出代码(python和C++): #coding=utf-8 from numpy import * ##定义训练集 def Get_traData(): """"创建6个数据,分别为A.B,C""" traData = ([1.3,3.1],[2.0,1.3],[5.1,9.0],[5.3,10.1],[8.2,1.4],[9.3,1.5]) labels = ['A','A','B','B','C','C'] return traData,labels ##KNN算法 def KNN(input,tradata,label,K): """求欧几里德距离""" dist = [] for i in range(len(tradata)): _x = tradata[i][0] - input[0] _y = tradata[i][1] - input[1] _x = _x ** 2 _y = _y ** 2 dist.append((_x+_y)**0.5) """对距离进行排序,返回坐标""" index = argsort(dist) """求出前K个最近距离中,每个标签各有多少个""" count = {} for i in range(K): tap = label[index[i]] count[tap] = count.get(tap,0)+1 """求出被标记最多次的标签""" flag = 0 result = '' for tap in count.keys(): if flag < count[tap]: flag = count[tap] result = tap return result data,l = Get_traData() input = [9.0,3.0] an = KNN(input,data,l,4) print (an)
|
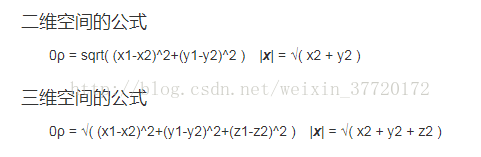

【本文地址】
公司简介
联系我们